
|
|
A Lösungen zu den Übungen
In diesem Anhang finden Sie die Lösungen zu den Übungen am Ende jedes Kapitels.
Lösungen zu den Übungen in Kapitel 2
- Wie Sie sehen, beginnt das Programm mit der typischen #!-Zeile; Ihr Pfad zu Perl kann sich davon unterscheiden. Außerdem haben wir die Warnungen eingeschaltet.
- Die erste richtige Codezeile füllt die Variable $pi mit dem Wert von p. Es gibt eine Reihe von Gründen, aus denen ein guter Programmierer wie hier gezeigt eine Konstante1 benutzen würde: Es kostet Zeit, 3.141592654 in Ihr Programm einzufügen, wenn Sie den Wert mehr als einmal brauchen. Zudem könnte es einen mathematischen Fehler bedeuten, wenn Sie an einer Stelle Ihres Programms 3.141592654 schreiben und 3.14159 an einer anderen. Auf die hier beschriebene Art gibt es nur eine Stelle in Ihrem Programm, an der Sie überprüfen müssen, ob Sie nicht versehentlich 3.141952654 eingegeben haben und Ihre Raumsonde dadurch womöglich zum falschen Planeten schicken. Es ist einfacher, $pi einzugeben als p, insbesondere, wenn es bei Ihnen keine Unicode-Unterstützung gibt.
- Außerdem ist Ihr Programm leichter zu pflegen, falls sich der Wert von p jemals ändern sollte.2
- Als nächstes berechnen wir den Umfang und legen den Wert in $umfang ab. Am Schluß wird dieser Wert in einer netten Nachricht ausgegeben. Die Nachricht endet auf ein Newline-Zeichen, da jede Ausgabezeile eines guten Programms dies tun sollte. Falls Sie kein Newline-Zeichen benutzen, sieht Ihre Ausgabe, abhängig vom Shell-Prompt, unter Umständen wie folgt aus:
Der Umfang eines Kreises mit dem Radius 12.5 ist 78.53981635.bash-2.01$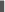
- Der graue Kasten am Ende der Zeile steht hierbei für die blinkende Einfügemarke. Der seltsame Text hinter Ihrer Nachricht ist die Eingabeaufforderung der Shell.3 Da der Umfang des Kreises eigentlich nicht 78.53981635.bash-2.01$, ist, könnte dies womöglich als Programmierfehler angesehen werden. Benutzen Sie also lieber \n am Ende jeder Ausgabezeile.
#!/usr/bin/perl -w $pi = 3.141592654; print "Wie lautet der Radius? "; chomp($radius = <STDIN>); $umfang = 2 * $pi * $radius; print "Der Umfang eines Kreises mit dem Radius $radius ist $umfang.\n";
- Dies ist fast das gleiche Programm wie in der vorigen Übung, nur daß wir hier die Variable $radius benutzen, wo vorher der unveränderliche Wert 12.5 stand. Hätten wir das erste Programm mit etwas mehr Weitsicht geschrieben, hätten wir auch dort schon die Variable $radius verwendet. Mit Hilfe des chomp-Operators entfernen wir das Newline-Zeichen am Ende der Zeile. Selbst wenn wir das nicht getan hätten, würde unser mathematischer Ausdruck noch funktionieren, da der String "12.5\n" für die Berechnung automatisch in die Zahl 12.5 umgewandelt wird. Geben wir am Ende des Programms jedoch die Nachricht aus, bekommen wir jetzt eine Ausgabe wie die folgende:
Der Umfang eines Kreises mit dem Radius 12.5 ist 78.53981635.
- Das liegt daran, daß das Newline-Zeichen sich immer noch in $radius befindet, auch wenn wir die Variable zwischenzeitlich als Zahl benutzt haben. Da sich in der print-Anweisung zwischen $radius und dem Wort "ist" ein Leerzeichen befindet, wird dieses nun als erstes Zeichen der zweiten Zeile ausgegeben. Die Moral von der Geschicht' lautet: Benutzen Sie chomp für Ihre Eingaben, es sei denn, Sie haben einen guten Grund, dies nicht zu tun.
#!/usr/bin/perl -w $pi = 3.141592654; print "Wie lautet der Radius? "; chomp($radius = <STDIN>); $umfang = 2 * $pi * $radius; if ($radius < 0) { $umfang = 0; } print "Der Umfang eines Kreises mit dem Radius $radius ist $umfang.\n";
- Hier haben wir einen Test auf einen ungültigen Radius eingebaut. Auf diese Weise wird bei einem ungültigen Radius jedenfalls kein negativer Wert mehr ausgegeben. Sie hätten auch den Radius auf null setzen können, um dann den Umfang zu berechnen, aber es gibt schließlich mehr als eine mögliche Lösung. Das ist übrigens das Motto von Perl: »Es gibt mehr als eine Lösung« (»There Is More Than One Way To Do It«, TIMTOWTDI). Aus diesem Grund beginnen die Lösungen zu den Übungen mit dem Satz: »So könnte eine mögliche Lösung aussehen.«
print "Bitte geben Sie die erste Zahl ein: "; chomp($eins = <STDIN>); print "Bitte geben Sie die zweite Zahl ein: "; chomp($zwei = <STDIN>); $ergebnis = $eins * $zwei; print "Das Ergebnis ist $ergebnis.\n";
- Beachten Sie, daß wir in dieser Antwort die #!-Zeile nicht mit angegeben haben. Von jetzt an gehen wir davon aus, daß Sie wissen, daß die Zeile da ist, damit Sie sie nicht jedesmal mitlesen müssen.
- Vermutlich ist die Wahl der Namen für die Variablen nicht besonders gelungen. In einem großen Programm könnte der Wartungsprogrammierer denken, die Variable $zwei solle den Wert 2 enthalten. In diesem kurzen Programm ist das wahrscheinlich noch nicht so wichtig, aber wir hätten die Variablen etwas verständlicher benennen können, beispielsweise $erste_antwort.
- In diesem Programm würde es keinen Unterschied machen, ob wir chomp benutzen oder nicht, da die Variablen $eins und $zwei nicht mehr als Strings benutzt werden, nachdem sie deklariert wurden. Ändert der Wartungsprogrammierer aber nächste Woche die ausgegebene Nachricht in etwas wie: Das Ergebnis der Multiplikation von $eins und $zwei ist $ergebnis.\n - werden uns diese elendigen Newline-Zeichen immer weiter verfolgen. Auch in diesem Fall gilt also: Benutzen Sie chomp,4 es sei denn, Sie haben einen guten Grund, dies nicht zu tun. Die folgende Übung zeigt einen solchen Fall.
print "Bitte geben Sie einen String ein: "; $string = <STDIN>; print "Bitte geben Sie eine Anzahl ein: "; chomp($anzahl = <STDIN>); $ergebnis = $string x $anzahl; print "Das Ergebnis ist:\n$ergebnis";
- Das Programm ist fast das gleiche wie das aus der letzten Übung. Hier »multiplizieren« wir einen String. Wir haben also die Struktur der vorigen Übungen beibehalten. Hier benutzen wir aber für den String kein chomp, da die Aufgabenstellung verlangte, die Strings auf eigenen Zeilen auszugeben. Hätte der Benutzer fred und ein Newline-Zeichen als String und 3 für die Zahl eingegeben, stünde nun hinter jedem Vorkommen automatisch ein Newline-Zeichen - und genau das wollten wir ja!
- In der print-Anweisung am Ende des Programms stellen wir dem $ergebnis ein zusätzliches Newline-Zeichen voran, damit das erste fred auch auf einer eigenen Zeile ausgegeben wird. Hätten wir das nicht getan, stünde des erste fred am Ende der ersten Zeile und die anderen zwei in einer Reihe untereinander:
Das Ergebnis ist: fred fred fred
- Gleichzeitig haben wir am Ende der print-Anweisung kein Newline-Zeichen angegeben, da $ergebnis dies bereits enthalten sollte.
- In den meisten Fällen ist es Perl egal, an welcher Stelle in Ihrem Programm Sie Leerzeichen benutzen. Sie können sie benutzen oder auch weglassen, ganz wie Sie wollen. Aber es ist wichtig, nicht versehentlich eine falsche Formulierung zu benutzen! Stünde der x-Operator direkt an dem davor stehenden Variablennamen $str, würde Perl hierin die Variable $strx sehen und das funktioniert nun einmal nicht.
Lösungen zu den Übungen in Kapitel 3
print "Bitte geben Sie einige Zeilen ein, und druecken Sie dann Ctrl-D:\n"; # oder auch Ctrl-Z @zeilen = <STDIN>; @zeilen_umgedreht = reverse @zeilen; print @zeilen_umgedreht;
- ...oder, noch einfacher:
print "Bitte geben Sie einige Zeilen ein, und druecken Sie dann Ctrl-D:\n"; print reverse <STDIN>;
- Die meisten Perl-Programmierer ziehen vermutlich die zweite Lösung vor, solange keine Liste der Zeilen für eine spätere Verwendung angelegt werden muß.
@namen = qw/ Fred Betty Barney Dino Wilma Pebbles Bambam /; print "Geben Sie zeilenweise ein paar Zahlen zwischen 1 und 7 ein, und druecken Sie dann Ctrl-D:\n"; chomp(@zahlen = <STDIN>); foreach (@zahlen) { print "$zahlen[ $_ - 1 ]\n"; }
- Wir müssen hier eins von der Index-Zahl abziehen, damit der Benutzer Zahlen von 1 bis 7 eingeben kann, obwohl die Arrayindizes von 0 bis 6 gehen. Eine andere Möglichkeit wäre die Verwendung eines Dummy-Elements in unserem @namen, und zwar wie folgt:
@namen = qw/ dummy_element Fred Betty Barney Dino Wilma Pebbles Bambam /;
- Schreiben Sie sich ein paar Zusatzpunkte gut, wenn Sie zusätzlich noch überprüft haben, ob die Benutzereingaben tatsächlich im Bereich zwischen 1 und 7 liegen.
chomp(@zeilen = <STDIN>); @sortiert = sort @zeilen; print "@sortiert\n";
- Um die Ausgaben auf ihren eigenen Zeilen darzustellen, können Sie auch folgendes schreiben:
print sort <STDIN>;Lösungen zu den Übungen in Kapitel 4
sub gesamt { my $summe; # private Variable foreach (@_) { $summe += $_; } $summe; }
- Diese Subroutine benutzt die Variable $summe, um den Gesamtwert zu speichern. Zu Beginn ist der Wert von $summe noch undef, da wir die Variable neu angelegt haben. (Noch einmal: Es gibt keine automatische Verbindung zwischen @_, dem Parameterarray, und $_, der Standardvariablen für die foreach-Schleife.)
- Beim ersten Schleifendurchlauf wird zur Variablen $summe die erste Zahl (in $_) hinzugezählt. Bis zu diesem Zeitpunkt ist der Wert von $summe selbstverständlich undef, da wir hier bisher noch nichts gespeichert haben. Da wir die Variable aber hier als Zahl benutzen (was Perl an dem numerischen Operator += erkennt), wird sie hier behandelt, als hätte sie bereits den Wert 0. Perl addiert zur ersten Zahl 0 hinzu und speichert das Ergebnis wieder in $summe.
- Beim nächsten Schleifendurchlauf wird der nächste Parameter zum Wert von $summe hinzuaddiert, der nun nicht länger undef ist. Die Summe von Parameter und Wert wird wiederum in $summe gespeichert. Dies wird nun so lange wiederholt, bis es keine Parameter mehr gibt und der Wert von $summe an die aufrufende Anweisung zurückgegeben wird.
- In dieser Subroutine gibt es eine mögliche Fehlerquelle, je nachdem wie Sie sich die Dinge vorstellen. Nehmen wir an, die Subroutine wäre mit einer leeren Parameterliste aufgerufen worden (worauf wir in der neugeschriebenen Subroutine &max im Kapitel selbst eingegangen sind). In diesem Fall wäre der Wert von $summe undef, und dieser Wert würde auch zurückgegeben. In der Subroutine wäre es aber vermutlich »korrekter«, statt dessen 0, zurückzugeben. (Wollten Sie das Ergebnis einer leeren Liste jedoch von der Summe aus (3, -5, 2) unterscheiden, indem Sie undef zurückgeben, wäre das auch nicht falsch.)
- Wollen Sie jedoch keine undefinierten Werte zurückgeben, so gibt es ein einfaches Mittel dagegen: Initialisieren Sie $summe einfach mit dem Wert 0 anstatt das standardmäßige undef zu benutzen:
my $summe = 0;
- Nun gibt die Subroutine immer einen Wert zurück, selbst wenn eine leere Parameterliste übergeben worden ist.
# Denken Sie daran, die Subroutine &gesamt aus der vorigen Übung # einzubauen! print "Die Zahlen von 1 bis 1000 ergeben zusammen", &gesamt(1..1000),".\n";
- Wir können die Subroutine nicht direkt aus einem String in doppelten Anführungszeichen heraus aufrufen.5 Statt dessen übergeben wir den Subroutinenaufruf einfach als weiteres Element der Liste, die print übergeben wird. Das Gesamtergebnis ist 500500, eine runde Summe. Hierbei sollten Sie kaum bemerken, wie die Zeit vergeht. Die Arbeit mit Parameterlisten, die tausend Werte enthalten, ist für Perl reine Routine.
Lösungen zu den Übungen in Kapitel 5
my %nachname = qw{ Fred Feuerstein Barney Geroellheimer Wilma Feuerstein }; print "Bitte geben Sie einen Vornamen ein: "; chomp(my $name = <STDIN>); print "Aha, Sie meinen $name $nachname{ $name }.\n";
- In diesem Fall benutzen wir eine qw//-Liste (mit geschweiften Klammern als Trennzeichen), um den Hash zu initialisieren. Solange wir mit einfachen Daten arbeiten, ist das völlig in Ordnung, da sowohl die Schlüssel als auch die Werte einfache Namen sind. Sobald Ihre Daten jedoch Leerzeichen oder anderes enthalten - zum Beispiel wenn Herr Müller-Lüdenscheidt oder Die sieben Zwerge Steintal einen Besuch abstatten - würde diese einfache Methode nicht mehr so gut funktionieren.
- Eventuell haben Sie sich entschieden, jedes Schlüssel/Wert-Paar für sich zuzuweisen, wie hier:
my %nachname; $last_name{"Fred"} = "Feuerstein"; $last_name{"Barney"} = "Geroellheimer"; $last_name{"Wilma"} = "Feuerstein";
- Beachten Sie, daß Sie Ihren Hash zuerst deklarieren müssen, bevor Sie ihm irgendwelche Werte zuweisen können. (Falls use strict benutzt wird, müssen Sie Ihren Hash mit my deklarieren.) Auf die folgende Art läßt sich my jedoch nicht benutzen:
my $nachname{"Fred"} = "Feuerstein"; # Hoppla!
- Der my-Operator funktioniert nur mit vollständigen Variablen, niemals mit einem einzelnen Element eines Arrays oder Hashs. Und wo wir gerade von lexikalischen Variablen reden: Es ist Ihnen vielleicht aufgefallen, daß die lexikalische Variable $name innerhalb des Funktionsaufrufs von chomp durchgeführt wird. Es kommt recht häufig vor, daß eine my-Variable, wie hier gezeigt, erst bei Bedarf deklariert wird.
- Dies ist ein weiterer Grund, warum die Verwendung von chomp so wichtig ist. Gibt jemand den aus fünf Zeichen bestehenden String "Fred\n" ein und vergessen wir, mit chomp das Newline-Zeichen zu entfernen, wird versucht, das Hashelement mit dem Schlüssel "Fred\n" zu finden, und das gibt es nicht. Natürlich ist auch die Verwendung von chomp nicht hundertprozentig wasserdicht. Gibt jemand beispielsweise den String "Fred \n" (mit einem Leerzeichen nach Fred) ein, hätten wir bis jetzt keine Möglichkeit herauszufinden, daß eigentlich Fred gemeint war.
- Falls Sie mit exists überprüft haben, ob der angegebene Schlüssel existiert, können Sie dem Benutzer zumindest mitteilen, daß ein Name offenbar falsch geschrieben wurde. Schreiben Sie sich ein paar Zusatzpunkte gut, wenn Sie das gemacht haben.
my(@woerter, %zaehler, $wort); # (optionales) Deklarieren der Variablen chomp(@woerter = <STDIN>); foreach $wort (@woerter) { $zaehler{$wort} += 1; # oder $zaehler{$wort} = $zaehler{$wort}+1; } foreach $wort (keys %zaehler) { # oder sort keys %zaehler print "$wort kam $count{$word} mal vor.\n"; }
- Hier haben wir alle Variablen zu Beginn des Programms deklariert. Wenn Sie vor Perl bereits andere Sprachen, wie etwa Pascal, gelernt haben (bei denen Variablen immer »am Anfang« deklariert werden), kommt Ihnen diese Methode vermutlich eher bekannt vor, als die Variablen erst zu deklarieren, wenn sie wirklich gebraucht werden. Wir deklarieren hier unsere Variablen auf jeden Fall, da wir davon ausgehen, daß standardmäßig use strict benutzt wird. Prinzipiell erwartet Perl solche Deklarationen jedoch nicht.
- Als nächstes benutzen wir den Zeileneingabe-Operator <STDIN> im Listenkontext, um alle Eingabezeilen in das Array @woerter einzulesen; danach wenden wir chomp auf alle eingelesenen Zeilen gleichzeitig an. Das Array @woerter enthält nun sämtliche eingegebenen Wörter als separate Elemente (sofern sie jeweils auf einer eigenen Zeile gestanden haben, wie es verlangt war, versteht sich).
- Nun geht die erste foreach-Schleife die Wörter durch. In der Schleife findet sich hierbei die wichtigste Anweisung des gesamten Programms. Hier wird zum Wert von $zaehler{$wort} eins hinzugezählt und das Ergebnis wieder in $zaehler{$wort} gespeichert. Sie können hier beide Schreibweisen benutzen, wobei die kurze Version (mit dem +=-Operator) ein wenig effizienter ist, da Perl das $wort im Hash nur einmal nachschlagen muß.6
- In der ersten foreach-Schleife zählen wir auf diese Weise zum Wert von $zeaehler{$wort} für jedes Wort eins hinzu. Wäre das erste Wort fred gewesen, würden wir nun also $zaehler{"fred"} um eins erhöhen. Da wir $zaehler{"fred"} hier jedoch zum erstenmal zu Gesicht bekommen, ist dessen Wert noch undef. Wir benutzen den Wert hier aber als Zahl (durch die Benutzung von += beziehungsweise +, falls Sie die lange Form gewählt haben), daher wandelt Perl diesen Wert automatisch von undef in eine 0 um. Schließlich wird er um eins erhöht, so daß $zaehler{"fred"} nun den Wert 1 besitzt.
- Nehmen wir an, beim nächsten Schleifendurchlauf laute das Wort barney. Nun addieren wir eins zu $zaehler{"barney"} und verwandeln so auch dessen Wert von undef in 1.
- Im dritten Schleifendurchlauf wird als Wort ein weiteres Mal fred eingegeben. Wir addieren zum Wert von $zaehler{"fred"} also erneut eins hinzu und erhöhen ihn so von 1 auf 2. Das Ergebnis wird auch hier wieder in $zaehler{"fred"} gespeichert, was bedeutet, daß wir fred zweimal gesehen haben.
- Wenn wir zum Ende der foreach-Schleife kommen, haben wir also ermittelt, wie oft jedes Wort eingegeben wurde. In unserem Hash gibt es für jedes (einmalige) Wort einen Schlüssel, wobei der dazugehörige Wert die Anzahl der Vorkommen des Wortes wiedergibt.
- Als nächstes durchläuft nun die zweite foreach-Schleife die Schlüssel unseres Hashs, also die eingegebenen Wörter. Wie bereits gesagt, kann ein Schlüssel jeweils immer nur einmal vorkommen. Bei jedem Schleifendurchlauf sehen wir also nun ein anderes Wort, für das wir eine Nachricht wie »fred kam 3 mal vor.« ausgeben.
- Wollen Sie sich mit dieser Lösung ein paar Zusatzpunkte verdienen, können Sie die Schlüssel (keys) vor der Ausgabe noch sortieren. Enthält die Ausgabeliste mehr als ein Dutzend Elemente, ist eine Sortierung empfehlenswert, da die Person, die das Programm debuggen muß, das gesuchte Element leichter finden kann.
Lösungen zu den Übungen in Kapitel 6
print reverse <>;
- Das ist aber einfach! Diese Formulierung funktioniert, weil print eine Liste von Strings erwartet. Diese bekommt es, indem es reverse im Listenkontext aufruft. reverse sucht seinerseits nach einer Liste von Strings, die es umdrehen kann. Diese bekommt es, indem es die vom Raumschiff-Operator zurückgegebenen Daten ebenfalls im Listenkontext benutzt. Der Raumschiff-Operator gibt eine Liste aller Zeilen der Dateien zurück, die der Benutzer angegeben hat. Diese Liste entspricht der Ausgabe von cat. reverse dreht diese Liste nun um, und print gibt sie aus.
print "Geben Sie einige Zeilen ein, und druecken Sie dann Ctrl-D:\n"; # oder Ctrl-Z chomp(my @zeilen = <STDIN>); print "1234567890" x 7, "12345\n"; # 75 Zeichen breites "Lineal" foreach (@zeilen) { printf "%20s\n", $_; }
- Wir beginnen damit, alle Textzeilen einzulesen und mittels chomp die Newline-Zeichen zu entfernen. Als nächstes geben wir unsere »Lineal«-Zeile aus. Da wir dies nur als Hilfe beim Debuggen brauchen, wird diese Zeile normalerweise auskommentiert, wenn unser Programm fertiggestellt ist. Wir hätten nun die Zeile "1234567890" so oft eingeben können, wie wir sie brauchen, oder sie einfach kopieren und einfügen können, um die »Lineal«-Zeile zu erzeugen. Statt dessen benutzen wir einfach den x-Operator.
- Schließlich iteriert die foreach-Schleife über unsere Liste und gibt dabei jede Zahl im Format %20s aus. Sie hätten aber auch ein Format erzeugen können, mit dem die Liste auf einmal ausgegeben wird, ohne dabei eine Schleife benutzen zu müssen:
my $format = "%20s\n" x @zeilen; printf $format, @zeilen;
- Häufig sind die Spalten versehentlich nur 19 Zeichen breit. Das geschieht, wenn Sie sich7 sagen: »Wozu wenden wir chomp auf den Inhalt an, wenn wir die Newline-Zeichen am Ende doch wieder einbauen müssen?«. Folglich lassen Sie das chomp weg und benutzen das Format "%20s" (ohne das Newline-Zeichen).8 Und plötzlich fehlt der Ausgabe ein Zeichen. Wie kann das sein?
- Das Problem tritt auf, wenn Perl die Anzahl der Leerzeichen zu berechnen versucht, die gebraucht werden, um Ihre Zeilen rechtsbündig auszugeben. Gibt der Benutzer Hallo und ein Newline-Zeichen ein, sieht Perl sechs Zeichen und nicht fünf, da auch der Zeilenumbruch ein Zeichen ist. Hieraufhin werden vierzehn Leerzeichen ausgegeben und ein String von sechs Zeichen Länge. Das ergibt genau die zwanzig Zeichen, die in der Formatangabe "%20s" vorgegeben waren. Hoppla!
- Perl sieht sich den Inhalt eines Strings nicht an, um die Breite zu ermitteln. Statt dessen werden einfach nur die enthaltenen Zeichen gezählt. Ein Newline-Zeichen (aber auch andere Zeichen, wie der Tabulator oder das NUL-Zeichen) bringen die Sache durcheinander.9
print "Wie viele Zeichen soll die Spalte breit sein? "; chomp(my $breite = <STDIN>); print "Geben Sie einige Zeilen ein, und druecken Sie dann Ctrl-D:\n"; # oder Ctrl-Z chomp(my @zeilen = <STDIN>); print "1234567890" x (( $breite + 9 ) / 10), "\n"; # "Lineal"-Zeile nach Bedarf anpassen foreach (@zeilen) { printf "%${breite}s\n", $_; }
- Dieses Programm funktioniert fast genau wie das vorige. Der einzige Unterschied besteht darin, daß wir nun den Benutzer einen Wert für die Breite angeben lassen. Wir holen diese Information zuerst ein, da auf manchen Systemen keine weiteren Daten mehr angegeben werden können, nachdem einmal das Dateiende-Zeichen benutzt wurde. In der Praxis würden Sie selbstverständlich eine bessere Methode benutzen, um das Ende der Eingabe zu ermitteln, wie wir in späteren Kapiteln sehen werden.
- Ein weiterer Unterschied zum vorigen Programm ist die Linealzeile. Wir haben hier ein bißchen Mathe benutzt, um die Linealzeile mindestens so breit zu machen, wie benötigt. Haben Sie das geschafft, gibt es auch hier einige Zusatzpunkte. Eine weitere Herausforderung besteht darin, zu beweisen, daß unsere Berechnungen auch richtig sind. (Tip: Es können auch Breiten wie 50 und 51 eingegeben werden. Bedenken Sie auch, daß die Zahlenangabe für x abgeschnitten und nicht gerundet wird.)
- Um das Format zu erzeugen, haben wir den Ausdruck "%${breite}s\n" verwendet, in dem die Variable $breite interpoliert wird. Die geschweiften Klammern werden hier gebraucht, um den Namen vom folgenden s zu isolieren. Ohne geschweifte Klammern würden wir versuchen, eine Variable mit dem Namen $breites, zu interpolieren. Alternativ hätten Sie für die Erzeugung des Format-Strings auch einen Ausdruck wie '%' . $breite . "s\n" einsetzen können.
- Durch die Verwendung von $breite haben wir eine weitere Situation, in der auf jeden Fall chomp verwendet werden muß. Tun wir das nicht, sähe der resultierende Format-String jetzt so aus: "%30\ns\n", was nicht besonders nützlich wäre.
- Leute, die printf bereits einmal gesehen haben, denken vielleicht an eine weitere Lösungsmöglichkeit. Da printf seine Wurzeln in C hat, das keine Interpolation in Strings besitzt, können wir den gleichen Trick wie die C-Programmierer anwenden. Wird anstelle einer numerischen Angabe für die Feldbreite ein Sternchen (*) benutzt, ersetzt Perl dieses durch die Angabe im ersten übergebenen Parameter.
printf "%*s\n", $breite, $_;Fußnoten
Falls Sie nach einer formelleren Art von Konstanten suchen, sollten Sie sich einmal das constant-Pragma ansehen.
Dies wurde durch eine Gesetzesänderung im US-Staat Indiana tatsächlich einmal fast gemacht. Details finden Sie unter http://www.urbanlegends.com/legal/pi_indiana.html.
Wir haben die Leute von O'Reilly gefragt, ob sie nicht zusätzlich Geld ausgeben wollten, um die Einfügemarke mit blinkender Tinte zu drucken. Der Vorschlag wurde leider abgelehnt.
Mampfen (chomping) ist wie kauen - es ist nicht immer nötig, tut meistens aber auch keinem weh.
Jedenfalls nicht ohne einige fortgeschrittene Tricks anzuwenden. Es ist aber selten, daß sich etwas in Perl überhaupt nicht erledigen läßt.
Zumindest in einigen Versionen von Perl sorgt die Kurzform dafür, daß keine Warnung über die Benutzung eines undefinierten Werts ausgegeben wird. Verwenden Sie den Autoinkrement-Operator, ++, gibt es ebenfalls keine Warnung, auch wenn Sie diesen bis jetzt noch nicht kennen.
Oder Larry, falls der neben Ihnen steht.